RPA의 핵심 OCR은 어떻게 발전해왔을까?
2025년 12월 17일

OCR 기술은 단순한 문자 인식에서 문맥 이해로 진화하며, RPA의 성공에 필수적이다. 비정형 데이터 처리의 필요성이 증가하면서, 최신 LLM 기반 OCR은 높은 정확도로 다양한 문서를 이해하고 처리할 수 있다. 이러한 기술 발전은 하이퍼오토메이션을 가능하게 하고, RPA의 범위를 확장하여 복잡한 업무를 자동화할 수 있는 기반을 마련한다. 그러나 보안 리스크와 비용 문제도 동반되며, 이를 해결하기 위한 다양한 전략이 필요하다.
RPA의 눈, OCR: 텍스트를 읽는 기술에서 맥락을 이해하는 뇌로 진화하다?
🍎 바쁘다면 알짜배기만이라도!
진화의 핵심 — 단순 패턴 매칭에서 트랜스포머(Transformer) 기반의 문맥 이해로, OCR은 단순한 '눈'에서 '뇌'를 가진 지능형 문서 처리(IDP)로 진화했습니다.
실패율의 비밀 — RPA 프로젝트의 약 30~50%가 실패하거나 기대 이하의 성과를 내는데, 그 핵심 원인은 기업 데이터의 80%를 차지하는 비정형 데이터(이미지, PDF 등)를 기존 룰 기반 봇이 처리하지 못하기 때문입니다.
기술적 도약 — 최신 LLM 기반 OCR은 전처리 없이 이미지를 통째로 이해하여, 손글씨나 구겨진 영수증 같은 노이즈가 심한 데이터에서도 99% 이상의 정확도를 달성하고 있습니다.
왜 지금 OCR인가?
기업의 디지털 전환(DX)이 가속화되면서 로보틱 프로세스 자동화(RPA)는 선택이 아닌 필수가 되었지만, 여전히 많은 기업이 '자동화의 역설'에 빠져 있습니다. 수억 원을 들여 구축한 RPA 봇이 왜 고작 송장 양식이 조금 바뀌었다고 멈춰 서는 걸까요?
답은 데이터의 형태에 있습니다. IBM의 분석에 따르면 기업 데이터의 약 80%는 이메일, PDF 계약서, 스캔 이미지와 같은 비정형 데이터이며, 기존의 전통적인 RPA는 엑셀이나 데이터베이스처럼 구조화된 데이터(Structured Data)만 처리할 수 있는 '눈 없는 일꾼'에 불과했기 때문입니다.
2024년 기준 글로벌 RPA 시장은 약 283억 달러(약 38조 원) 규모로 성장했지만, 진정한 하이퍼오토메이션(Hyperautomation)을 실현하기 위해서는 이 비정형 데이터를 기계가 읽을 수 있는 형태로 변환해주는 OCR(Optical Character Recognition, 광학 문자 인식) 기술이 반드시 선행되어야 합니다.
과거의 OCR이 단순히 이미지 속의 글자를 '추측'하는 수준이었다면, 2025년의 OCR은 LLM(거대언어모델)과 결합하여 문맥을 '이해'하고 누락된 정보를 추론하는 단계로 진입했습니다. 이제 우리는 텍스트를 읽는 것을 넘어, 문서의 의도를 파악하는 기술적 변곡점에 서 있습니다.
OCR의 기술적 해부: 픽셀에서 의미로
OCR은 마법이 아니라 정교한 수학과 알고리즘의 집합체입니다. 우리가 스마트폰으로 영수증을 찍을 때, 그 찰나의 순간 내부에서는 이미지 전처리부터 후처리까지 최소 5단계 이상의 복잡한 공정이 숨 가쁘게 돌아갑니다.
1단계: 전처리(Pre-processing), 기계가 읽기 좋은 밥상 차리기
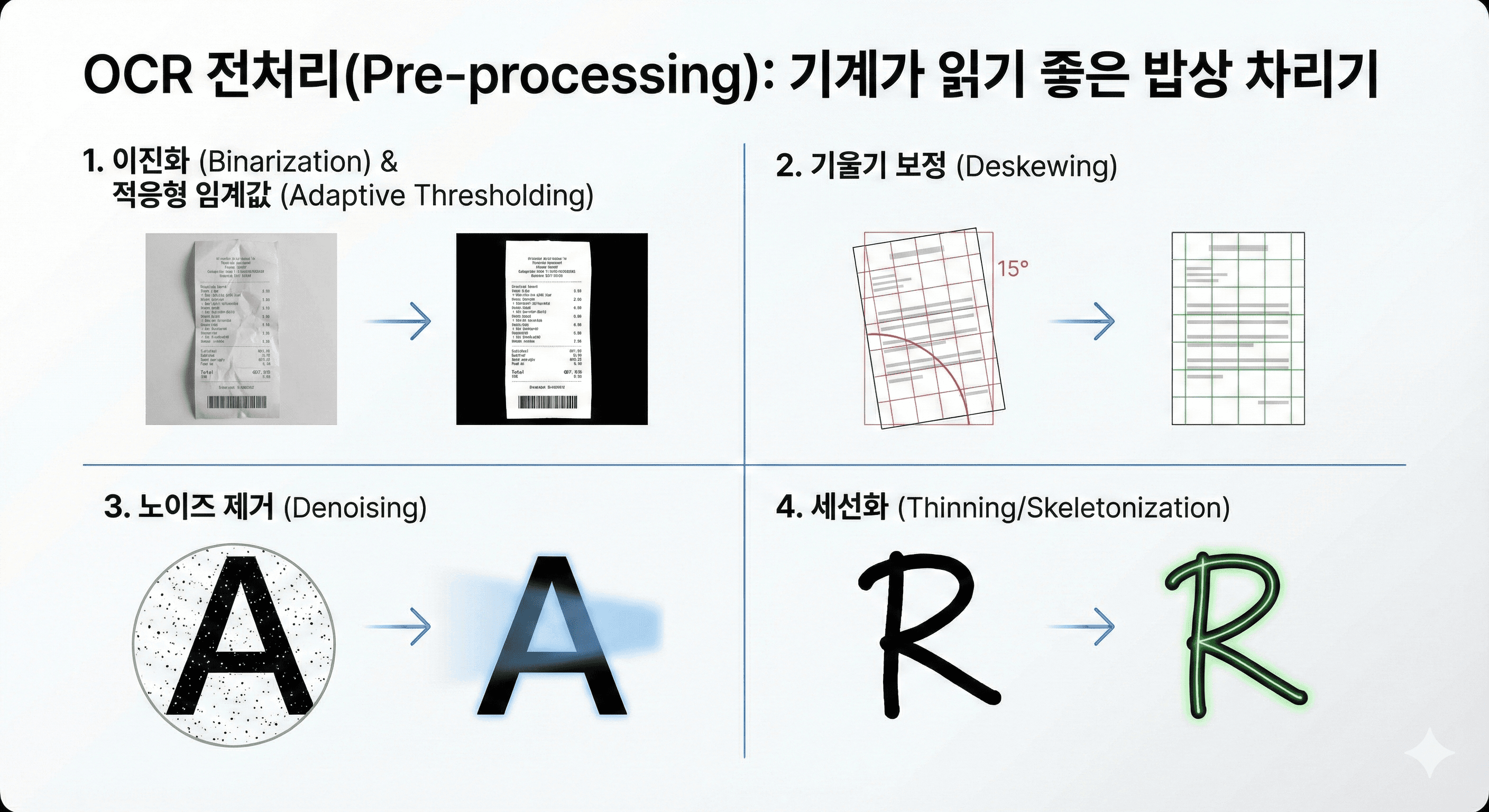
원본 이미지는 기계에게 너무나 불친절합니다. 조명이 어둡거나, 종이가 구겨지거나, 얼룩이 묻어있기 일쑤이기 때문입니다. 전처리는 이러한 노이즈를 제거하여 인식률을 극대화하는 가장 중요한 단계로, 전체 OCR 성능의 50% 이상을 좌우한다고 해도 과언이 아닙니다.
가장 먼저 수행되는 이진화(Binarization)는 컬러나 회색조(Grayscale) 이미지를 흑백(0과 1)으로 변환하여 데이터의 복잡도를 낮춥니다. 이때 단순히 밝기 기준값(Threshold)을 고정하는 것이 아니라, '적응형 임계값(Adaptive Thresholding)' 알고리즘을 사용하여 이미지의 각 부분마다 주변 밝기에 따라 다른 기준을 적용합니다. 이는 그림자가 진 문서에서도 글자를 선명하게 분리해내는 핵심 기술입니다. 오츠의 알고리즘(Otsu's method) 같은 기법은 배경과 글자의 명암 분포(Histogram)를 분석하여 최적의 임계값을 자동으로 찾아내, 빛바랜 영수증에서도 텍스트를 살려냅니다.
다음으로 기울기 보정(Deskewing)이 필수적입니다. 스캐너나 카메라로 찍은 문서는 미세하게 기울어져 있는 경우가 많은데, 단 1~2도의 기울기만으로도 텍스트 라인 인식이 완전히 어긋날 수 있습니다. 투영 프로파일(Projection Profile) 방법이나 허프 변환(Hough Transform)을 사용하여 텍스트 줄의 각도를 계산하고, 이미지를 역으로 회전시켜 수평을 맞춥니다.
또한 노이즈 제거(Denoising) 과정을 통해 스캔 과정에서 발생한 점(Salt and Pepper noise)이나 얼룩을 제거합니다. 가우시안 필터(Gaussian Filter)나 미디언 필터(Median Filter) 같은 평활화 기법이 사용되는데, 이는 글자의 엣지(Edge)는 살리면서 배경의 자잘한 노이즈만 뭉개버리는 역할을 합니다. 마지막으로 손글씨 인식의 경우, 글자의 획 굵기가 제각각이기 때문에 글자의 뼈대만 남기는 세선화(Thinning/Skeletonization) 과정을 거쳐 글자의 구조적 특징을 명확히 합니다.
2단계: 세그멘테이션(Segmentation), 의미 단위로 조각내기
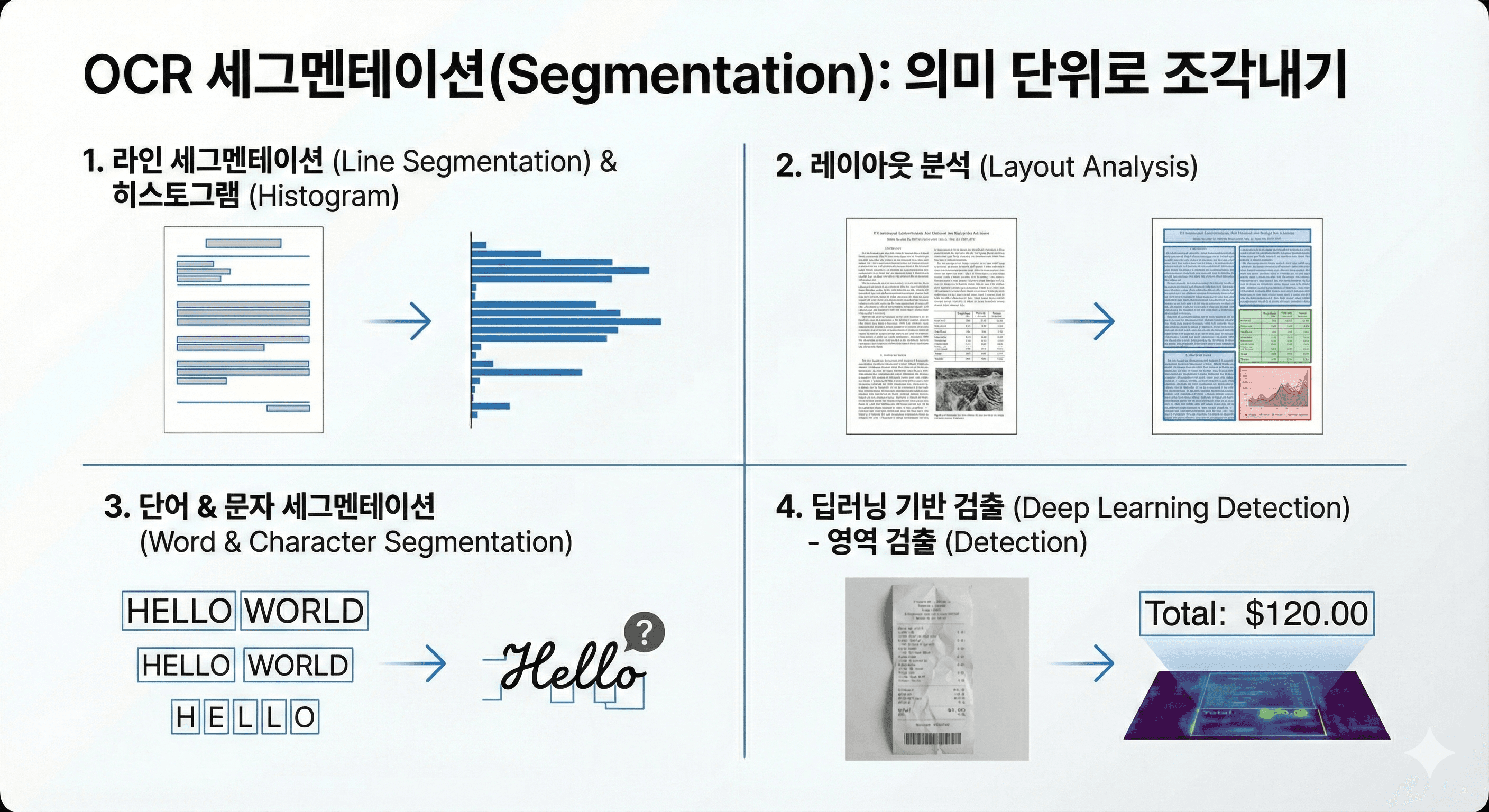
전처리가 완료된 깨끗한 이미지는 이제 분석 가능한 단위로 쪼개져야 합니다. 이 과정은 크게 라인(Line) → 단어(Word) → 문자(Character) 단위로 계층적으로 이루어집니다.
라인 세그멘테이션은 텍스트의 수평 히스토그램을 분석하여 픽셀 밀도가 높은 구간(글자 줄)과 낮은 구간(줄 간격)을 구분하는 방식으로 작동합니다. 하지만 문서가 다단으로 편집되어 있거나 표(Table)가 포함된 경우, 단순 히스토그램 방식은 실패할 확률이 높습니다. 이때는 레이아웃 분석(Layout Analysis) 알고리즘이 개입하여 문서의 구조를 먼저 파악하고 텍스트 영역과 비텍스트 영역(이미지, 그래프 등)을 분리합니다.
단어와 문자 세그멘테이션은 글자 사이의 간격(White space)을 분석하여 수행되는데, 특히 한글이나 영어 필기체처럼 글자가 이어져 있는 경우(Cursive script)가 가장 큰 난관입니다. 이를 해결하기 위해 현대적인 OCR은 문자를 억지로 자르지 않고 전체를 하나의 시퀀스로 인식하는 방식을 채택하기도 합니다. 최근의 딥러닝 모델들은 이 과정을 명시적으로 수행하지 않고, 이미지 전체의 특징 맵(Feature Map)에서 직접 텍스트 영역을 검출(Detection)하는 방식을 선호합니다.
3단계: 특징 추출(Feature Extraction), 글자의 DNA 찾기
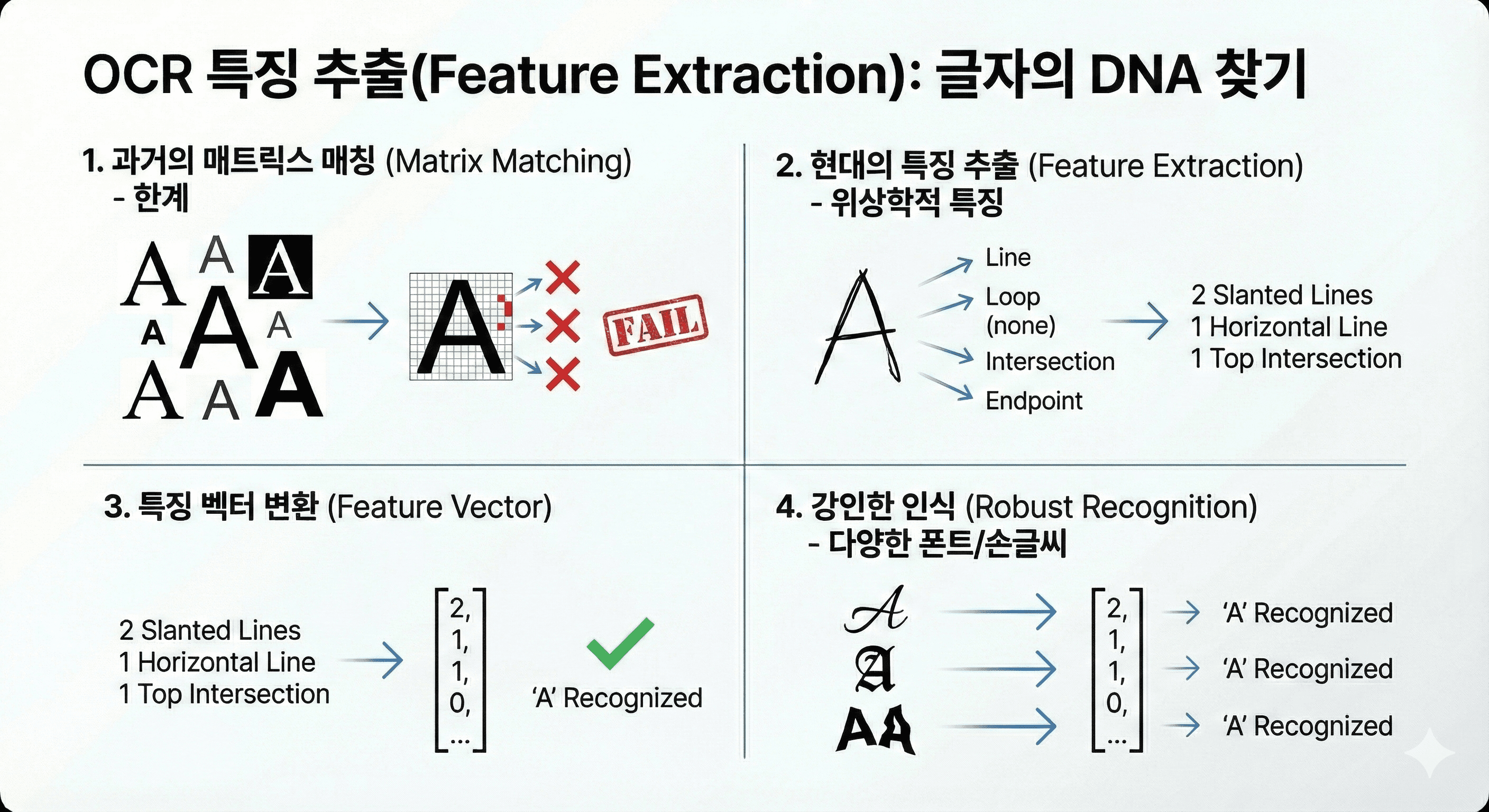
잘라낸 조각이 'A'인지 'B'인지 판단하기 위해, 기계는 해당 이미지의 고유한 특징을 뽑아냅니다. 과거의 매트릭스 매칭(Matrix Matching) 방식은 저장된 폰트 템플릿과 픽셀 단위로 비교하는 방식이었으나, 폰트나 크기가 조금만 달라져도 인식하지 못하는 치명적인 한계가 있었습니다.
현대의 OCR은 특징 추출(Feature Extraction) 방식을 주로 사용합니다. 이는 글자를 픽셀이 아닌 선(Line), 루프(Loop, 닫힌 원), 교차점(Intersection), 끝점(Endpoint), 획의 방향(Direction)과 같은 위상학적 특징들의 집합으로 이해합니다. 예를 들어 'A'는 '두 개의 기울어진 선과 중간의 가로선, 그리고 상단의 교차점'이라는 특징 벡터(Vector)로 변환됩니다. 이 방식은 손글씨나 다양한 폰트에도 강인한 인식 성능을 보여줍니다.
4단계: 분류(Classification), 이것은 무엇인가?
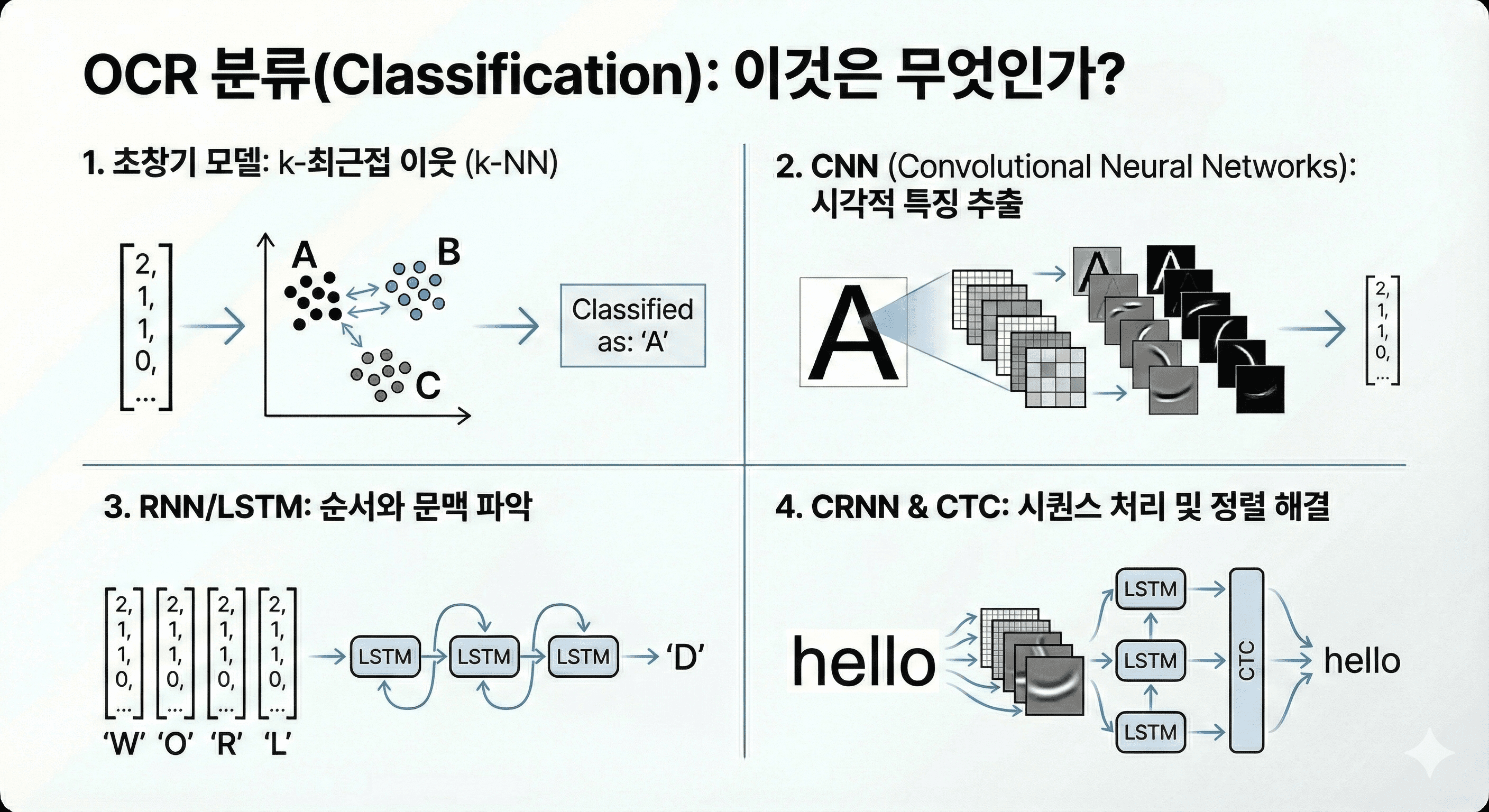
추출된 특징 벡터는 분류기(Classifier)에 입력되어 최종적인 문자로 판별됩니다. 초창기에는 k-최근접 이웃(k-NN)과 같은 통계적 모델이 사용되었으나, 현재는 딥러닝(Deep Learning) 모델이 표준으로 자리 잡았습니다.
특히 CNN(Convolutional Neural Networks)은 이미지의 시각적 특징을 추출하는 데 탁월하며, RNN(Recurrent Neural Networks), 그중에서도 LSTM(Long Short-Term Memory)은 문자의 순서와 문맥을 파악하는 데 사용됩니다. 이 두 가지를 결합한 CRNN(Convolutional Recurrent Neural Network) 아키텍처는 이미지 속의 텍스트를 시퀀스로 처리하여 비약적인 인식률 향상을 이끌어냈습니다. CTC(Connectionist Temporal Classification) 손실 함수를 사용하여 입력 이미지 시퀀스와 출력 텍스트 시퀀스 간의 정렬(Alignment) 문제를 해결한 것이 결정적이었습니다.
5단계: 후처리(Post-processing), 문맥으로 교정하기
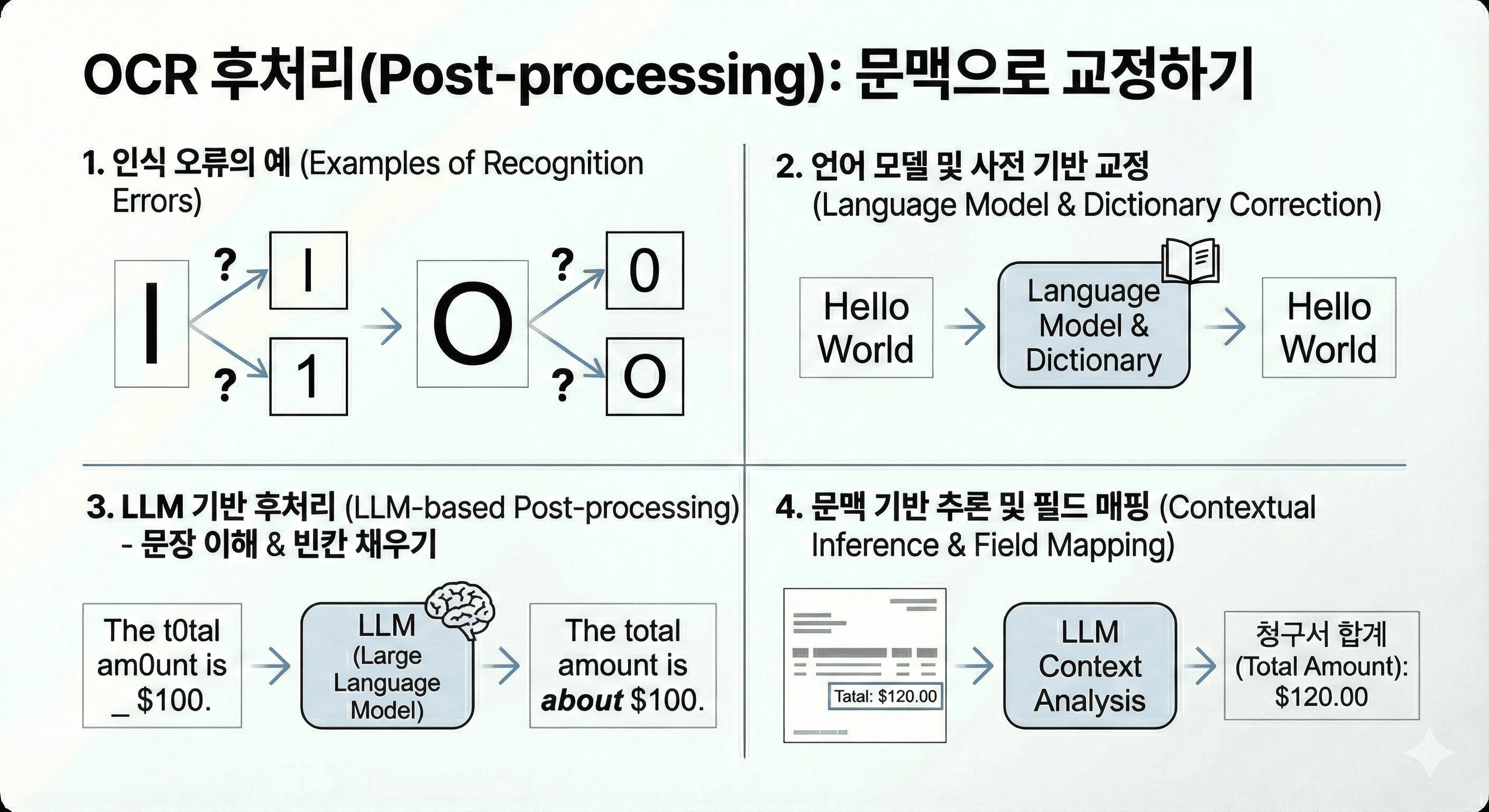
아무리 뛰어난 알고리즘도 'l(소문자 엘)'과 '1(숫자 일)', '0(숫자 영)'과 'O(대문자 오)'를 완벽하게 구별하기는 어렵습니다. 후처리 단계에서는 언어 모델(Language Model)과 사전(Dictionary)을 활용하여 인식된 결과의 오류를 교정합니다.
예를 들어, "HeIlo World"라고 인식되었다면, 언어 모델은 'I'가 올 자리가 아님을 확률적으로 계산하고 사전을 참조하여 "Hello"로 수정합니다. 최근에는 LLM(Large Language Model)을 후처리기(Post-processor)로 활용하여, 단순 철자 교정을 넘어 문장 전체의 의미를 파악하고 누락된 단어를 채워 넣거나 문서의 카테고리를 분류하는 수준까지 발전했습니다. 심지어 오탈자가 있더라도 전체 문맥상 "청구서의 합계 금액"이라는 것을 유추하여 정확한 필드에 매핑하는 것이 가능해졌습니다.
진화의 계보: 템플릿에서 트랜스포머까지
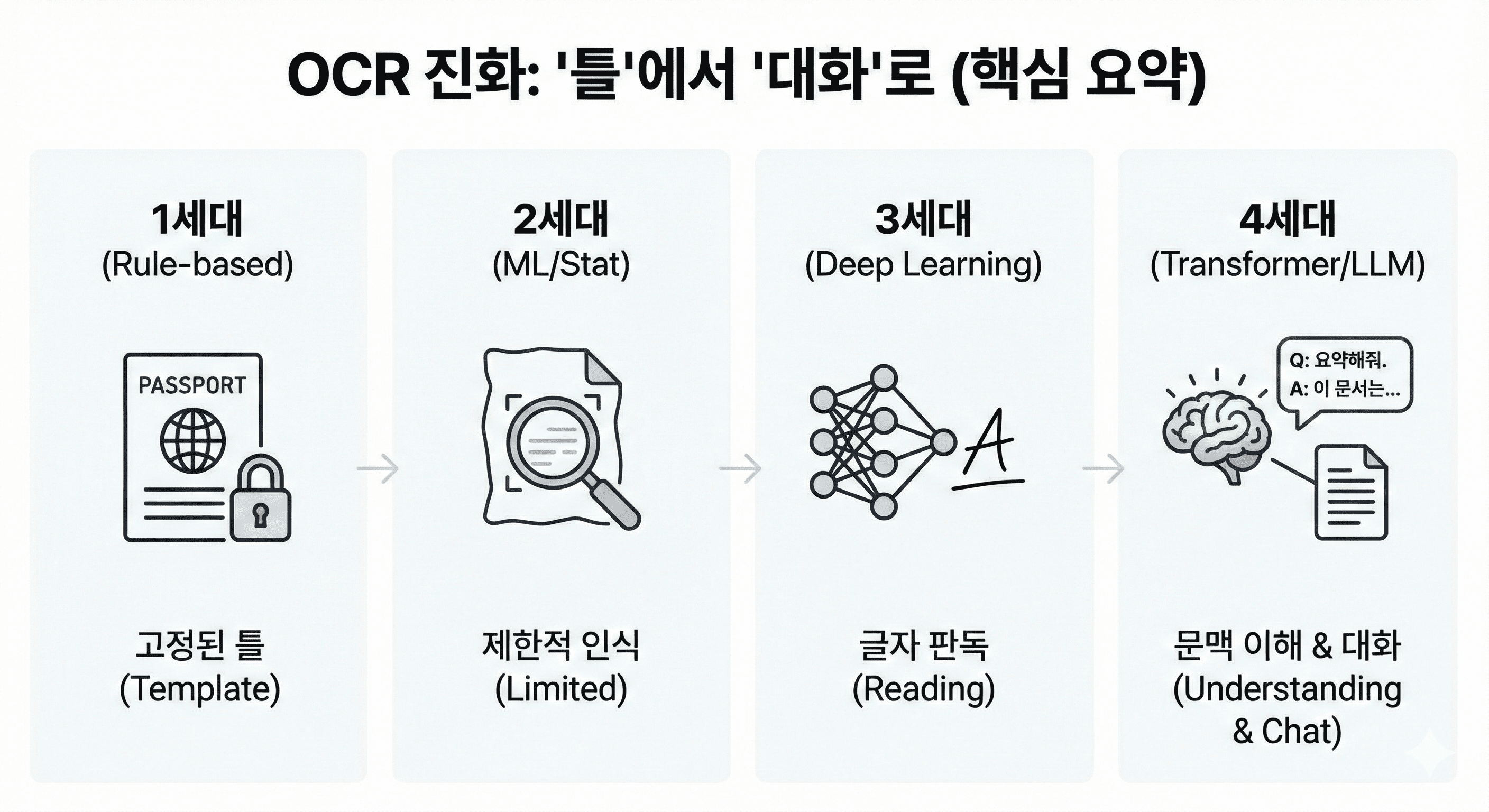
OCR 기술은 지난 수십 년간 4세대에 걸쳐 진화해왔으며, 각 세대의 변화는 RPA의 적용 범위를 비약적으로 넓혀왔습니다.
1세대: 규칙 기반 및 템플릿 OCR (Rule-based & Template OCR)
초기의 OCR은 템플릿 매칭에 의존했습니다. 사전에 정의된 폰트와 레이아웃이 아니면 인식하지 못했기 때문에, 여권이나 OMR 카드처럼 양식이 고정된 문서 처리에만 제한적으로 사용되었습니다. "송장 번호는 항상 우측 상단 좌표 (X, Y)에 있다"는 식의 규칙을 일일이 하드코딩해야 했으며, 양식이 조금만 바뀌어도 재설정이 필요했습니다. 이는 RPA 프로젝트의 유지보수 비용을 폭증시키는 주원인이었습니다.
2세대: 머신러닝 및 통계적 OCR (Machine Learning OCR)
SVM(Support Vector Machine)과 같은 머신러닝 알고리즘이 도입되면서, 다양한 폰트와 약간의 노이즈를 견딜 수 있게 되었습니다. 2000년대 중반부터 상용화된 ABBYY FineReader나 Tesseract 3.x 버전이 여기에 해당합니다. 하지만 여전히 비정형 문서의 복잡한 레이아웃이나 필기체 인식에는 한계가 뚜렷했습니다. Zonal OCR이라 불리는 이 기술은 특정 구역(Zone)을 지정하여 데이터를 추출하는 방식이었으나, 구역 설정이 어긋나면 무용지물이었습니다.
3세대: 딥러닝 기반 OCR (Deep Learning OCR)
2010년대 후반, 딥러닝의 등장은 OCR의 패러다임을 바꿨습니다. CNN이 이미지의 특징을 스스로 학습하고, LSTM이 문맥을 파악하면서 인식률이 비약적으로 상승했습니다. Tesseract 4.0부터 LSTM 엔진이 탑재되었고, 네이버의 Clova OCR, Google Vision API 등이 이 시기에 등장하여 필기체 인식과 복잡한 배경 속 텍스트(Scene Text) 인식까지 가능하게 했습니다. 이 시기부터는 문서의 레이아웃이 조금 바뀌어도 유연하게 대처할 수 있게 되었습니다.
4세대: 트랜스포머와 멀티모달 LLM (Transformer & GenAI OCR)
지금 우리는 4세대의 한복판에 있습니다. 자연어 처리(NLP)를 혁신한 트랜스포머(Transformer) 아키텍처가 비전(Vision) 영역으로 넘어오면서, ViT(Vision Transformer) 기반의 모델들이 등장했습니다.
가장 혁신적인 변화는 OCR-Free 모델의 등장입니다. Donut (Document Understanding Transformer)이나 Nougat 같은 모델은 이미지를 텍스트로 변환하는 중간 과정(Text Detection -> Recognition)을 생략하고, 이미지를 입력받아 곧바로 구조화된 데이터(JSON, Markdown)를 출력합니다. 기존 방식이 텍스트 박스를 찾고(Detection) 그 안의 글자를 인식(Recognition)하는 2단계 파이프라인을 거쳤다면, Donut은 이미지를 통째로 인코더(Encoder)에 넣고 디코더(Decoder)가 텍스트를 생성하는 엔드투엔드(End-to-End) 방식입니다. 이는 OCR의 고질적인 문제인 '오류 전파(Error Propagation)'를 원천 차단하고 처리 속도를 획기적으로 높였습니다.
또한 GPT-4V, Gemini와 같은 멀티모달 LLM(Multimodal LLM)은 이미지와 텍스트를 동시에 이해합니다. "이 영수증에서 총액이 얼마야?"라고 물으면, LLM은 'Total'이라는 글자의 위치뿐만 아니라 문서의 구조적 맥락을 파악하여 정확한 값을 찾아냅니다. 이는 사전에 템플릿 학습이 전혀 필요 없는 제로샷(Zero-shot) 추출을 가능하게 하여 RPA의 유연성을 극대화했습니다.
"2025년의 OCR은 단순히 글자를 읽는 것이 아니라, 문서와 대화하는 수준에 도달했습니다."
RPA의 심장, 왜 OCR이 가장 중요한가?
RPA(Robotic Process Automation)는 '팔'이고, OCR은 '눈'입니다. 눈이 보이지 않는 팔은 아무리 빠르고 강력해도 할 수 있는 일이 제한적입니다. RPA와 OCR의 결합이 필수적인 기술적, 비즈니스적 이유는 명확합니다.
1. 비정형 데이터의 장벽 (The Unstructured Data Barrier)
기업 업무의 핵심인 송장, 계약서, 이메일, 신분증 등은 대부분 비정형 데이터입니다. 2024년 기준, 기업 데이터의 80% 이상이 비정형 데이터로 추산됩니다. OCR 없이는 RPA가 이 데이터에 접근할 수 없으며, 이는 자동화 가능한 업무 영역이 전체의 20%에 불과하다는 것을 의미합니다. OCR은 이 비정형 데이터를 RPA가 이해할 수 있는 구조화된 데이터(XML, JSON, CSV)로 변환해주는 유일한 관문입니다.
2. 하이퍼오토메이션의 전제 조건 (Enabler of Hyperautomation)
단순 반복 업무를 넘어선 '하이퍼오토메이션'은 RPA, AI, 머신러닝, 프로세스 마이닝 등을 결합하여 자동화의 범위를 확장하는 개념입니다. 여기서 OCR은 IDP(Intelligent Document Processing, 지능형 문서 처리)의 핵심 엔진으로 작동합니다. IDP는 OCR로 텍스트를 추출하고, NLP로 의미를 이해하며, 머신러닝으로 데이터를 분류하고 검증합니다. 이 과정이 없이는 RPA가 의사결정이 필요한 복잡한 업무(예: 보험 청구 심사, 대출 승인)를 수행할 수 없습니다.
3. 실패 비용 최소화 (Reducing Failure Rates)
RPA 프로젝트의 실패 원인 중 상당수는 '데이터 품질'과 '예외 처리'에 있습니다. 입력 데이터가 표준화되지 않아 봇이 에러를 일으키는 것입니다. 고성능 AI-OCR은 다양한 레이아웃과 노이즈가 섞인 문서에서도 일관된 품질의 데이터를 추출하여 RPA 봇의 안정성을 높입니다. 실제로 OCR 통합을 통해 데이터 처리 비용을 40% 절감하고, 처리 시간을 60% 단축했다는 연구 결과는 OCR이 RPA 성공의 핵심 변수임을 증명합니다.
딥다이브: 차세대 OCR 모델의 기술적 차별점
2024~2025년 기술 트렌드에서 주목해야 할 최신 OCR 모델들은 기존의 한계를 어떻게 극복했을까요?
TrOCR (Transformer-based OCR)
마이크로소프트가 개발한 TrOCR은 CNN과 트랜스포머를 결합한 하이브리드 구조입니다. 이미지를 패치(Patch) 단위로 쪼개어 ViT(Vision Transformer)로 인코딩하고, 이를 BERT나 RoBERTa 같은 언어 모델 디코더로 텍스트를 생성합니다. 기존의 CNN+RNN 구조보다 병렬 처리가 용이하고, 사전 학습된 언어 모델의 지식을 활용하기 때문에 언어 이해도가 훨씬 높습니다. 특히 인쇄체뿐만 아니라 난이도가 높은 필기체 인식(SROIE, IAM 데이터셋)에서도 SOTA(State-of-the-Art) 성능을 기록했습니다.
Donut (Document Understanding Transformer)
네이버 클로바가 제안한 Donut은 OCR-Free라는 파격적인 접근을 취합니다. 기존 방식이의 파이프라인을 거쳤다면, Donut은 이미지를 입력받아 곧바로 구조화된 JSON을 출력합니다. 중간 단계가 없기 때문에 속도가 빠르고, 텍스트 인식 오류가 정보 추출 단계로 전파되는 문제를 근본적으로 해결했습니다. 특히 영수증이나 송장처럼 구조가 복잡한 문서 처리에 탁월합니다.
LayoutLMv3
마이크로소프트의 LayoutLM 시리즈는 텍스트 정보뿐만 아니라 레이아웃(위치 정보)과 이미지(시각 정보)를 동시에 학습하는 멀티모달 모델입니다. LayoutLMv3는 텍스트 임베딩, 레이아웃 임베딩, 이미지 임베딩을 하나의 트랜스포머 모델에 통합하여 학습합니다. "문서의 우측 상단에 굵은 글씨로 쓰여진 숫자는 높은 확률로 송장 번호일 것이다"라는 식의 시각적 추론이 가능합니다. 이는 표나 복잡한 서식(Form)을 이해하는 데 독보적인 성능을 보여줍니다.
Nougat (Neural Optical Understanding for Academic Documents)
메타(Meta)가 공개한 Nougat은 과학 논문이나 기술 문서 처리에 특화된 모델입니다. 수식, 표, 각주 등이 포함된 복잡한 PDF 문서를 마크다운(Markdown) 형식으로 완벽하게 변환합니다. 기존 OCR이 수식을 깨진 문자로 인식하던 것과 달리, Nougat은 수식을 LaTeX 코드로 정확하게 복원해냅니다. 이는 학술 데이터나 기술 매뉴얼을 RAG(검색 증강 생성) 시스템에 연동할 때 필수적인 기술이 되고 있습니다.
장점만 있는거야?
물론 장밋빛 미래만 있는 것은 아닙니다. LLM 기반 OCR의 도입은 새로운 보안 위협과 비용 문제를 야기하고 있습니다.
보안 리스크: 프롬프트 인젝션과 데이터 유출
LLM은 사용자의 입력(프롬프트)을 그대로 실행하려는 성향이 있어, 악의적인 사용자가 문서 내에 숨겨진 명령어를 심어놓을 경우 모델이 오작동하거나 내부 데이터를 유출할 수 있습니다(Prompt Injection). 또한, 민감한 개인정보나 금융 정보가 포함된 문서를 클라우드 기반 LLM에 전송하는 과정에서 데이터 주권 및 프라이버시 침해 우려가 있습니다.
대응 전략
PII 마스킹(Masking): LLM에 전송하기 전에 로컬 모델을 사용하여 민감 정보를 비식별화합니다.
Enterprise LLM: 데이터가 학습에 사용되지 않는 기업용 프라이빗 LLM이나 온프레미스(On-premise) 모델(Llama 3, Mistral 등)을 활용합니다.
입출력 필터링: 프롬프트와 생성된 결과물에 대한 보안 필터를 적용하여 악성 명령어를 차단합니다.
환각(Hallucination)과 정확도 문제
LLM은 모르는 내용도 아는 것처럼 지어내는 환각 현상이 있습니다. OCR 결과에서 숫자를 잘못 읽거나 없는 내용을 생성한다면 금융/법률 분야에서는 치명적입니다.
대응 전략
Grounding & Validation: 추출된 데이터의 출처(좌표)를 명시하게 하고, 수학적 검증(예: 합계 검증)이나 외부 DB와의 교차 검증을 수행하는 로직을 추가합니다.
Human-in-the-Loop (HITL): 신뢰도가 낮은 결과에 대해서는 반드시 담당자의 검수를 거치도록 워크플로우를 설계합니다.
비용과 지연 시간(Latency)
LLM은 기존 경량 OCR 모델에 비해 연산 비용이 높고 처리 속도가 느립니다. 수백만 장의 문서를 실시간으로 처리해야 하는 환경에서는 LLM이 비효율적일 수 있습니다.
대응 전략
하이브리드 파이프라인: 단순한 문서는 기존의 빠르고 저렴한 OCR(Tesseract, PaddleOCR)로 처리하고, 복잡하고 비정형화된 문서만 LLM으로 처리하는 이원화 전략을 사용합니다.
OCR, 자동화의 인지(Cognitive) 혁명
OCR은 더 이상 단순한 '문자 판독기'가 아닙니다. RPA와 결합한 OCR은 기업의 비정형 데이터를 정형 데이터로 변환하여, 자동화의 혈관에 데이터를 공급하는 '심장' 역할을 하고 있습니다.
트랜스포머와 LLM 기술의 도입으로 OCR은 템플릿의 속박에서 벗어나, 인간처럼 문서를 이해하고 추론하는 단계로 진화했습니다. 이는 RPA가 단순 반복 업무를 넘어, 판단과 의사결정이 필요한 고부가가치 업무로 영역을 확장할 수 있는 길을 열어주었습니다.
결국, 성공적인 RPA 프로젝트의 열쇠는 "얼마나 잘 누르느냐(Click)"가 아니라 "얼마나 잘 읽고 이해하느냐(Read & Understand)"에 달려 있습니다.
*이 글에 활용된 이미지는 Gemini3.0을 통해서 제작되었습니다.
인용 및 출처
RPA Failures: 10 Most Common Reasons and How to Avoid Them - Floboticsflobotics.io/blog/rpa-failures
Nougatfacebookresearch.github.io/nougat
TrOCR Object Detection Model: What is, How to Use - Roboflowroboflow.com/model/trocr
RPA, 시스템 자동화
시작하기 막막하신가요?
우리 기업에 딱 맞는 자동화를 어떻게 시작해야할지 어려우신 상황이라면 인바이즈를 찾아주세요.
다른 인사이트도 찾아보세요.
더 다양한 인사이트가 준비되어 있습니다.






